
beersomme
Intro and Motivation
I’m what you might call a beer connoisseur. I love trying new beer. Not only that, but I like to keep track of what beer I’m drinking and where I’m drinking that beer. Luckily, there’s an app for that. Untappd is a social network for beer aficionados, like myself. Users can “check-in” the beer they are currently drinking and the place they’re drinking it. Untappd also lets the user harness that check-in information. For example, a user can search to see if a specific beer is nearby. The app searches through nearby check-ins to find the most recent place that beer was checked-in. While its not perfect, the check-ins act as a proxy for beer list information. But what if I’m in New York craving a Dragoon IPA, a delicious IPA from Tucson, Arizona. I know I can’t find that in New York — and as expected, the search fails. But if we can’t find that particular beer, certainly we can find something similar. This is what inspired me to create beersomme — if I’m craving a certain beer, have an app find similar beers nearby to recommend the best place to go have a beer (or two).
The App
beersomme is an app I created over the course of three weeks at Insight Data Science. The app makes bar recommendations based on the user’s location and beer preference.
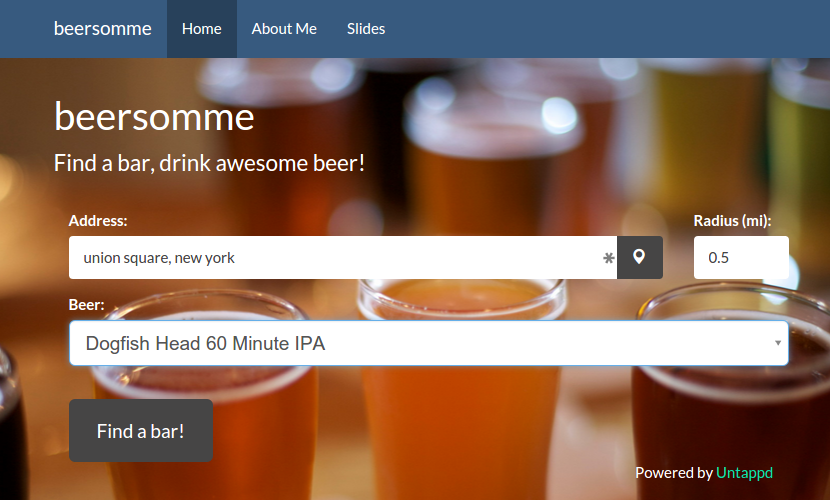
On the welcome page, the user is prompted for three pieces of information.
- Location
- The user can specify an address, landmark, or click on the location button to use the device’s current location.
- Radius
- This can be thought of as a maximum distance the user is willing to travel. The app will search for bars within a radius around the location specified.
- Beer
- Choose a beer from a searchable dropdown menu
For example, let’s look for bars near Union Square in New York City with beers similar to “Dogfish Head 60 Minute IPA”. So we’re looking for a sessionable IPA with citrus and floral notes. Let’s see what we can find…
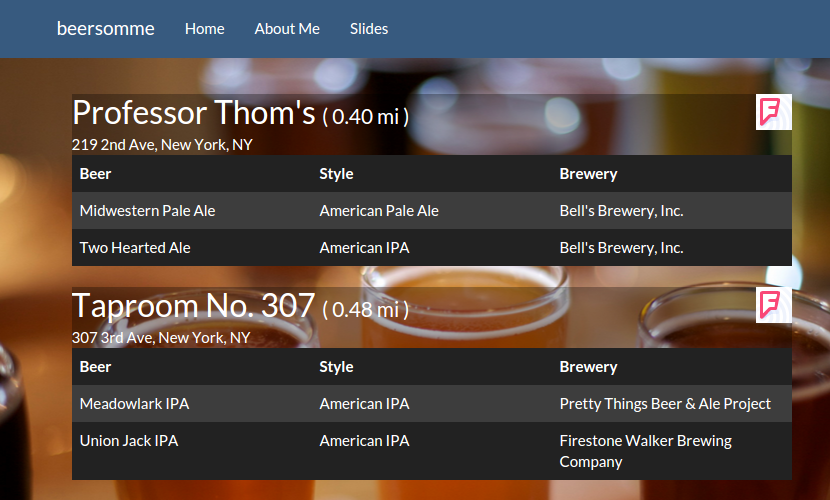
The output page provides a list of nearby bars that have beers similar to “Dogfish Head 60 Minute IPA” available on tap. The top two recommendations are to check out Professor Thom’s and Taproom No. 307. Each bar is recommended because each has two beers on tap that are of similar style, IPA or Pale Ale — beers with hoppy flavors. The process for determining beer similarity will be discussed below. For additional information about the bar, the user can click on the Foursquare link in the top right corner of each listing.
Technology Behind the Beer
The app consists of three parts:
- Local bar/beer list data collection and lookup
- Recommendations based on beer descriptions
- User Interface
Below is a schematic of the data flow with methods and technologies shown:
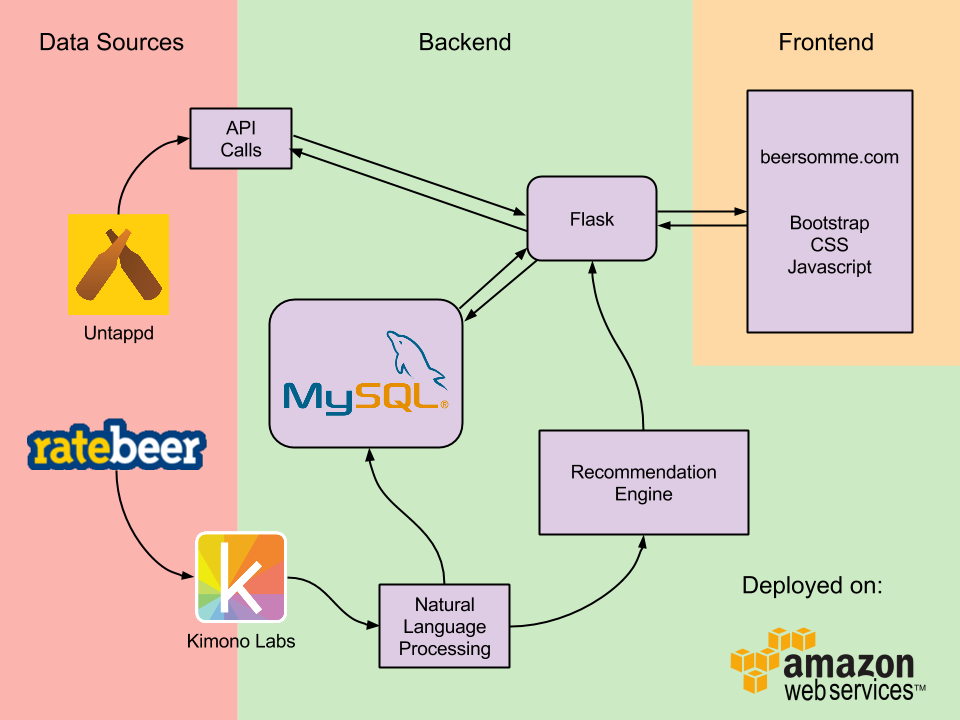
Essentially, beersomme is combining two beer resources to provide meaningful recommendations on where to find your next beer.
The Data
The data behind beersomme comes from two data sources, Untappd and Ratebeer. Untappd contributes local beer information. This provides information about what and where people are drinking. The Ratebeer site contains the beer descriptions used to determine which beers are most similar to each other.
Untappd Pipeline
The app uses the Untappd API to get local information to generate beer lists at nearby bars. By querying the local feed, I can find the most recent check-ins by Untappd users. This preliminary query finds information about where people are drinking. I then make additional API calls for each newly discovered bar to find the most recent check-ins. The check-ins from each bar can be used as a proxy for the current beer list.
In order to limit the number of API calls the app makes to Untappd, I employ a caching mechanism to store bar and beer information locally using a MySQL database. The app first checks whether there is sufficient information in the local database before making additional API calls.
To summarize the workflow:
- A beersomme user initiates a search for nearby bars
- Query the local database to look for bars within the specified region
- If not enough bars and beers are cached:
- Make API calls to the local feed to get a list of bars nearby
- Make additional API calls for each bar to collect enough beers to approximate the beer list
- Store newly found beers, bars, and check-ins in the local database
- Pass bar and beer list information to the recommender
Scraping Ratebeer
While data retrieval from the Untappd API occurs in a well structured manner, scraping Ratebeer requires additional work. I wrote a Python script to acquire a list of about 5000 US beer URLs from Ratebeer.com. This script utilized the Python package Beautiful Soup for parsing the HTML tree. I used the webapp from Kimono Labs to automate the scraping task of extracting the commercial description from each beer URL.
Text Processing
The goal is to reduce the raw description text to a cleaned collection of words. We can then represent a beer as a vector in word space, so that we can quantify similarity. This process is known as Natural Language Processing (NLP). I utilize two python packages for NLP: NLTK and scikit-learn.
Bag of Words
For each beer description, I strip formatting and punctuation, so that the description can be vectorized. Each beer can now represented as a list of word-occurence pairs, such as:
{'hoppy': 3, 'citrusy': 1, 'refreshing': 1, ...}
This is known as a bag-of-words model. Each description is transformed into a list of word counts, where word ordering no longer matters. In future iterations of beersomme higher order n-grams, such as bigrams could prove useful in retaining some of the word ordering information.
Next, I remove all words that will not help in representing beers. These include all words that only occur once throughout the corpus, the entire body of text. I also remove stop words, the common glue words in sentences (a, the, etc…).
Now, I can represent each beer as a sparse vector of word counts. The vector is \(n\)-dimensional, where \(n\) is the number of unique words in the corpus. The values in each dimension correspond to the frequency of the word in each beer description. In order to deal with additional common words that may pop up (beer, malt, etc…), I use a tf-idf (term frequency – inverse document frequency) weighting. This down-weights words that occur frequently throughout the corpus. Conversely, it up-weights words that occur rarely in individual beer descriptions. Performing this analysis on my corpus of beers results in the creation of a term-document matrix, or in my case, a keyword-beer matrix. This is a sparse matrix with dimension: \((\rm nwords ~\times ~ \rm nbeers)\). I will use this matrix to determine beer similarity.
Beer Similarity
For each column of the keyword-beer matrix, I have a beer vector in word space. Next, I need to choose a distance metric to determine which beers are closest to each other. Since the vectors are normalized (from tf-idf) I use a cosine similarity distance metric. So distance is measured by the angle of separation between the two vectors as follows:
\[\cos(\theta) = \frac{A \cdot B}{\lvert A \rvert ~ \lvert B \rvert}\] So if I have two beers, \(A\) and \(B\), they can be represented in some word space as shown here, separated by some angle
\(\theta\). Since these word vectors are positive (there can be no negative counts of word appearance), the angle \(\theta\) varies between \([0^\circ, 90^\circ]\) and correspondingly \(\cos(\theta)\) varies between \([1, 0]\), ranging from identical beers to completely different.
So if I have two beers, \(A\) and \(B\), they can be represented in some word space as shown here, separated by some angle
\(\theta\). Since these word vectors are positive (there can be no negative counts of word appearance), the angle \(\theta\) varies between \([0^\circ, 90^\circ]\) and correspondingly \(\cos(\theta)\) varies between \([1, 0]\), ranging from identical beers to completely different.
Applying the cosine similarity on each pair of beers, we can create a beer similarity matrix \(M\), where \(M_{ij}\) corresponds to the similarity between beer \(i ~\&~ j\).
Front End
The bulk of the front end is powered by Flask, a micro web application framework written in Python. Flask is used to interface between the HTML layer and backend components. For example, Flask will redirect user calls on the website to the appropriate backend Python process. Using this information, Flask will dynamically generate webpages built from Bootstrap templates. The site is deployed on Amazon Web Services in an EC2 instance.
Validation
Besides using the eye test (or taste test in this case), we need a way to validate that the recommender is working properly. We need an answer to the following questions. Can I use a simple bag-of-words method to identify beers? Will this provide sufficient information to separate disparate beer styles?
Let’s try to visualize this “flavor space”. I use singular value decomposition to reduce the dimension of the word space and plot three different styles of beer: IPA, Porter and Wheat.
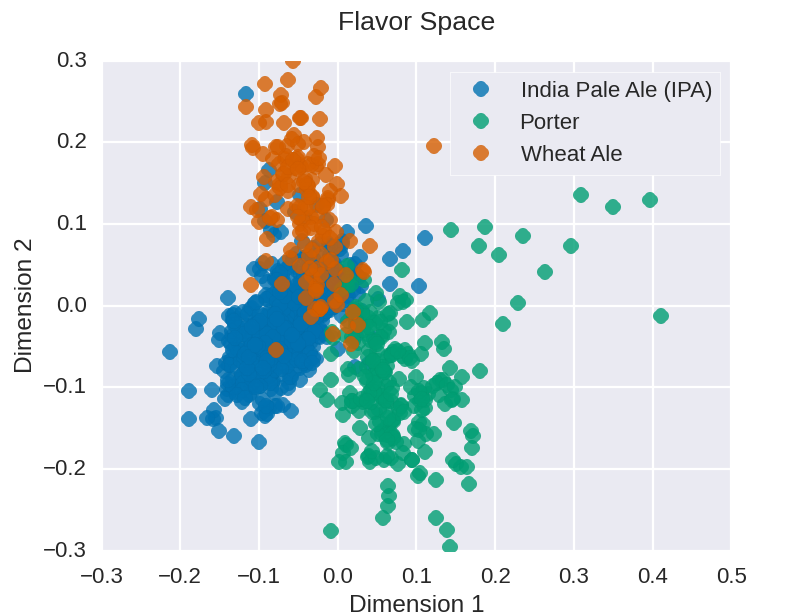
As you can see, there is a strong separation between these three differing beer styles. Examining the keywords that appear in the descriptions of beers in these three regions, we see the prominence of following flavors:
- Top left (Wheat): refreshing, crisp
- Bottom left (IPA): hoppy, bitter
- Bottom right (Porter): dark, rich
These flavors match well with the beer styles represented in those regions. We see that the beer description data are robust. The bag-of-words method is sufficient in separating beers by style into localized clusters. As a result, beersomme will recommend beers of similar style due to their proximity in the graph. We also see that recommendations across styles can occur for outlier beers of a given style.
Future Work
The current version of beersomme works quite well, but is far from complete. Additional work can be done in the following areas.
Improvements:
- More robust way of matching beers across databases (Ratebeer and Untappd)
- Use additional NLP techniques beyond Bag-of-Words
- Provide reasoning as to why certain beers are recommended (which flavors match). Use Latent Semantic Analysis.
Closing Thoughts
This project was built in three weeks during the Insight Data Science Program. I enjoyed learning and implementing new technologies to create beersomme. Building this project gave me the opportunity to learn and apply new techniques including natural language processing, recommender systems, and web scraping. Enjoy drinking awesome beer using beersomme!
If you have any questions about this project feel free to contact me at jonathan.eckel@gmail.com or tweet me at @jonathan_eckel. Or dive into the code on GitHub.